Formatting is one of the software development features that always steers controversy. To put it bluntly, everybody wants to format the code their own way. In previous SQL Dev versions the answer to that challenge was having elaborate tree-table widget spiced with several dozens of various options.
Arguably, the combined SQL and PL/SQL grammar is the most cumbersome programming language in existence, with total number of grammar productions exceeding 20000. From that perspective, the list of “Advanced Format” options offered by SQL Dev feels inadequate. To address this mismatch, the latest release introduced “Custom Format”. It offers to a developer means to specify formal conditions which SQL and PL/SQL grammatical constructs to indent, align, pad, add extra line breaks and so on.
As usual, the best way to demonstrate a new feature is an example. Consider the following enhancement request by Stefan Poschenrieder to remove the indent of the NOT NULL ENABLE inline constraint in the following code
CREATE TABLE dim_aspect ( dim_aspectid NUMBER(11,0) NOT NULL ENABLE, source VARCHAR2(50), hier1_desc VARCHAR2(50), hierarchy1 VARCHAR2(50), dwh_inserteddate DATE );
The first step is identifying the target grammar symbol in the Code Outline panel. Here is screen snapshot illustrating it:
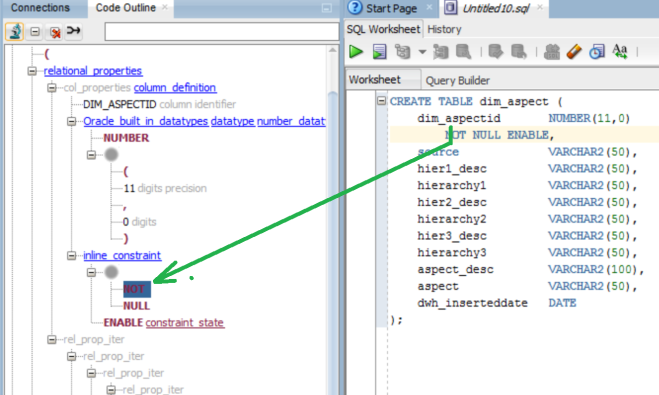
As illustrated there, positioning a cursor over the NOT keyword highlights the corresponding node in the parse tree. Therefore, the grammar symbol of interest is probably “inline_constraint“. Clicking onto the node labeled inline_constraint to double check this guess witnesses it highlighting “NOT NULL ENABLE” in the code editor. (Please be aware that clicking onto a hyperlinked looking grammar symbol has side effect of opening documentation page featuring that symbol railroad diagram definition).
As soon as the grammar symbol of interest is known, lets find it at Custom Format preferences panel. Admittedly, glaring omission there is the search widget. Yet, grammar symbols are arranged in lexicographic order, so that a reader would have no trouble spotting inline_constraint in the following formatting rule:
...
| [node) index_subpartition_clause[69,119)#
| [node) inline_constraint & 
Hey Vladim,
As the new SQLDeveloper is out, I try to bring together a custom format.
I want to align the declaration items to default expressions to get from this:
DECLARE
tot_emps NUMBER;
tot_depts NUMBER := 50;
v_verylongresultname VARCHAR2(32767) := ”;
v_val VARCHAR2(50) := ”;
v_onechar VARCHAR2(1) := ‘I’;
something like this:
DECLARE
tot_emps NUMBER;
tot_depts NUMBER := 50;
v_verylongresultname VARCHAR2(32767) := ”;
v_val VARCHAR2(50) := ”;
v_onechar VARCHAR2(1) := ‘I’;
I tried to use this alignment code inside paddedIdsInScope, but does not work:
| [id) constrained_type & [id+1) ‘:’ & [id+1+1) ‘=’ & [scope) decl_list
In the code outline it shows constrained_type (or unconstrained_type) should be used as id there but I’m stuck. Any idea what’s going wrong here?
Regards,
Daniel Nyeste
Oh well, blog engine doesn’t like white spaces apperently. Please look at my example at the following pastebin:
https://pastebin.com/5Zada6gV
You want the next node at the same level:
| [id) constrained_type & [id+1) default_expr_opt & [scope) decl_listHere is parse tree fragment:
[28,37) basic_decl_item
. [28,36) basic_d object_d
. . [28,29) decl_id identifier
. . [29,36) object_d_rhs
. . . [29,33) constrained_type
. . . . [29,30) 'VARCHAR2' unconstrained_...
. . . . [30,33) constraint paren_expr_list
. . . . . [30,31) '('
. . . . . [31,32) and_expr arg arith_expr ...
. . . . . [32,33) ')'
. . . [33,36) default_expr_opt
. . . . [33,34) ':'
. . . . [34,35) '='
. . . . [35,36) and_expr arith_expr boolean...
. [36,37) ';'
Output:
DECLARE tot_emps NUMBER; tot_depts NUMBER := 50; v_verylongresultname VARCHAR2(32767) := ''; v_val VARCHAR2(50) := ''; v_onechar VARCHAR2(1) := 'I'; BEGIN NULL; END;Hey Vadim,
Thank you for your help despite the mistake I made in your name the first time. I’m really sorry for that.
On the other hand, your answer works correctly 🙂
Regards,
Daniel
I’m trying to deploy SQLcl as an auto-formatting solution for our team project, that is use it in a Git hook. I’m almost there, but I really wish Oracle would bundle `format.arbori` into code style XML. Because code style XML embeds an absolute path to `format.arbori`, it seems to me that I have to:
1. Update code style XML and replace absolute path each time I export.
2. cd/pushd in my script to tun sqlcl from a fixed directory to use this relative path.
3. Do some shell programming to resolve relative file paths because of #2.
Can you suggest any better options? If not, can embedding be channelled as a SQL Developer enhancement somewhere?
The default formatting program — format.prg — is read from oracle.dbtools-common.jar (oracle/dbtools/app). If you replace it with your custom version, then you can disseminate the modified SQLcl (or just oracle.dbtools-common.jar) to the members of your team.
P.S. I agree that formatter not recognizing relative path to the formatting arbori program is a bug.
To be clear: it does recognize relative paths to format.arbori, but only relative to the current directory, which makes the whole thing clunky. I did finish a portable script that I could commit to a repo, but it’d have been easier to deal with a single code style XML.
Thanks for your response!
I’m looking for a condition that creates Line Breaks after ‘(‘ . I want move subquery one line higher and ‘)’ on end subquery. Can you help me?
One major shortcoming of 17.2 formatter is that there is no dedicated rule for line breaks. Line breaks are artifacts of indents, which limits what can be done with custom format. In 17.3 there is a separate rule for line breaks before and after a specified parse tree node. There I was able to achieve something sensible
SELECT 1 FROM dual WHERE 1 = ( SELECT 1 FROM dual )with “Line breaks->subqueries” option, and
SELECT 1 FROM dual WHERE 1 = ( SELECT 1 FROM dual )without.
P.S. this option looks broken in 17.2
Hi Vadim,
I l.ike to use leading comma in the column list i SELECT statement so I set “Line break” to be “Before Comma” in the Fomatting Options.
Unfortunately this also makes some function calls harder to read.
Example:
— Unformatted
SELECT M.MATERIAL
, SUBSTR(M.MATERIAL, 1, INSTR(M.MATERIAL, ‘:’, -1, 1) – 1) MATERIAL_SHORT
…
— After format:
SELECT M.MATERIAL
, SUBSTR(
M.MATERIAL
, 1
, INSTR(
M.MATERIAL
, ‘:’
, -1
, 1
) – 1
) MATERIAL_SHORT
…
Is there a way to exempt the commas within function calls from the Line Break rule?
Thanks.
NP
This area has been improved for upcoming release 17.3 (due in couple of weeks at the end of the quarter). Here is default formatting:
SELECT m.material, substr(m.material,1,instr(m.material,':',-1,1) - 1) material_short FROM dualAnd with leading commas:
SELECT m.material ,substr(m.material,1,instr(m.material,':',-1,1) - 1) material_short FROM dualIn 17.3 there are several notable improvements:
1. Dedicated rules for line breaks
2. A new advanced format option not to indent procedure arguments (default setting “no indent”)
3. Dedicated rules to override excessive line breaks, so that, for example, line break is never inserted before semicolon.
4. All advanced formatting options are “wired” into the custom format program so that they effectively turn on and off custom formatting rules, which results in more robust formatting job.
All these amendments warrant a blog post .
Please help me to get this format
— create_package_body.htm#LNPLS01381
CREATE OR REPLACE PACKAGE BODY emp_mgmt AS
tot_emps NUMBER;
tot_depts NUMBER;
FUNCTION hire ( last_name VARCHAR2 ,
job_id VARCHAR2 ,
manager_id NUMBER ,
salary NUMBER ,
department_id NUMBER ) RETURN NUMBER IS
new_empno NUMBER;
BEGIN
SELECT CASE “1”
WHEN 1
THEN ‘XX’
END
INTO new_empno
FROM emp,
dual d1,
dual d2
WHERE ( 1 = 2 OR 3 = 4 )
AND 0 = 1 + 2
AND EXISTS ( SELECT 1,
2,
3
FROM wsh_new_deliveries wnd
JOIN wsh_delivery_assignments wda ON wnd.delivery_id = wda.delivery_id
JOIN hz_locations hl ON hps.location_id = hl.location_id
);
INSERT INTO employees
VALUES ( new_empno,
‘First’ || ‘Middle’ || ‘Last’,
‘(415)555-0100′,
TO_DATE(’18-JUN-2002′,’DD-MON-YYYY’),
‘IT_PROG’,
90,
100,
110
);
tot_emps := tot_emps + 1; — := alignment
out_rec.var_char1 := in_rec1.first_name;
out_rec.var_char2222 := in_rec1.last_name;
CASE /* PL/SQL CASE operator formal syntax is different from SQL CASE expression */
WHEN 100 < salary
THEN
dbms_output.put_line('100 a1,– => alignment
p11 => a1,
p2 => a2
);
return(new_empno);
END;
END emp_mgmt;
/
Here is how to adjust the function header in 17.3:
1. Remove indentation of the first parameter:
2. Align second, third, and other parameters to the first one:
pairwiseAlignments5: [predecessor) prm_spec & [node) prm_spec & ( predecessor=node^-1 | predecessor=node^^-1 | predecessor=node^^^-1 | predecessor=node^^^^-1 ) ; pairwiseAlignments: pairwiseAlignments1 | pairwiseAlignments2 | pairwiseAlignments3 | pairwiseAlignments4 | pairwiseAlignments5 ->; ;3. Remove linebreak before closed parenthesis:
Result:
CREATE OR REPLACE PACKAGE BODY emp_mgmt AS FUNCTION hire ( last_name VARCHAR2, job_id VARCHAR2, manager_id NUMBER, salary NUMBER, department_id NUMBER ) RETURN NUMBER IS new_empno NUMBER; BEGIN NULL; END; END emp_mgmt; /Formatting for an expression list in an IN predicate inserts a trailing comma and a line break after each expression in an expression list.
WHERE
type IN (
19,
20,
21
)
I wanted to get rid of the line breaks (also before the opening paren), but couldn’t figure out how to do it.
WHERE
type IN (19,20,21)
Is this possible. I’m using 17.3.
ignoreLineBreaksAfterNode:
!:breaksAfterComma & [node) ','
| [node) ',' & [node-1) "expr_list" ---- add this line
| :breakAfterIf & [node) pls_expr & [node-1) 'IF'
->
;
Awesome, much obliged.
Hi,
Please help me to get this format.
CURRENT :
SELECT substr(
s.text,1,500
),
upper(
s.text
),
s.line
|| ‘ – ‘
|| s.text
FROM dba_errors e,
dba_source s
WHERE s.name = e.name
AND e.line = s.line
ORDER BY e.name,
e.sequence;
EXPECTED:
SELECT substr(s.text,1,500),
upper(s.text),
s.line|| ‘ – ‘ || s.text
FROM dba_errors e,
dba_source s
WHERE s.name = e.name
AND e.line = s.line
ORDER BY e.name,
e.sequence;
Advanced Format Settings:
-no breaks on concatenation
-no breaks after SELECT/FROM/WHERE
Thank you so much Vadim.
I solved the concatenation. However SUBSTR and UPPER continues to exceed the bottom line.
Hi Vadim,
Version 17.3 has improved a lot in formatting – great job, guys!
I’ve been struggling with :breaksAfterConcat. I see you added it into _extraBrkAfter section, which doesn’t implement indentation. How do I make concatenated nodes aligned?
Also, if I have nested concatenations, breaksAfterConcat inserts a new line regardless of the level. For example,
v.age_in_years || ‘ ‘ || nvl2( v.dob, ‘(‘ || to_char( v.dob, ‘mm/dd/yyyy’ ) || ‘)’, ‘ ‘ ) age_in_years
gets transformed into
v.age_in_years
|| ‘ ‘
|| nvl2( v.dob, ‘(‘ || to_char( v.dob, ‘mm/dd/yyyy’ )
|| ‘)’, ‘ ‘ ) age_in_years
So I cheated and added the following lines into ignoreLineBreaksBeforeNode:
| [node^^) “expr_list”
| [node^^^) “expr_list”
| [node^^^^) “expr_list”
But I suspect, this is not an ideal solution.
Could you advise, please?
Thanks!
The crux of the problem is what we consider desirable formatting for infix binary operator. Is
the most natural format? I would argue that binary operations should be represented in a way similar to parse tree:
1 + 2 + 3 + ( 4 + 5 + 6 )but don’t think any SQL developer would agree:-)
Philosophy aside, here one possibility:
resulting in
SELECT v.age_in_years || ' ' || nvl2(v.dob,'(' || TO_CHAR(v.dob,'mm/dd/yyyy') || ')',' ') age_in_years FROM dual;And here is another:
SELECT v.age_in_years || ' ' || nvl2( v.dob,'(' || TO_CHAR(v.dob,'mm/dd/yyyy') || ')',' ' ) age_in_years FROM dual;Thank you, Vadim. Both solutions worked well when select/from/where is checked in Advanced Format.
However, if the box is unchecked, the formatting looks like this –
#solution 1
select v.patient_identifier , v.age_in_years || ' ' || nvl2( v.dob, '(' || to_char( v.dob, 'mm/dd/yyyy' ) || ')', ' ' ) age_in_yearsIndentation didn’t work here.
#solution 2
select v.patient_identifier , v.age_in_years || ' ' || nvl2( v.dob, '(' || to_char( v.dob, 'mm/dd/yyyy' ) || ')', ' ' ) age_in_yearsNested indentation didn’t work here.
Guess I need to get used to a line break after select/from/where 🙂
Align the concatenation symbols to preceeding expression:
pairwiseAlignments1: predecessor = node-1 & (
…
| [predecessor) expr & [node) compound_expression[25,44)
);
SELECT v.patient_identifier, v.age_in_years || ' ' || nvl2(v.dob,'(' || TO_CHAR(v.dob,'mm/dd/yyyy') || ')',' ') age_in_yearsThank you, Vadim!
One more question:
select 1 from dual where 1 = 1 and 222222 = 222222 and 3 = 3 ;How do I align the first condition in the where clause?
This is a bug, which I don’t know any workaround.
How do i right align the keywords. I need the below o/p
SELECT a,
b,
c
FROM table1
WHERE a = 1
AND b = 2;
Hi Vadim!
Firstly, thank you for all the articles. They’ve been great.
I’d still however very much appreciate some help with the following example:
https://pastebin.com/Lx0i4atq
So far I added:
| [node-1) ‘(‘ & [node) prm_spec
to ignoreLineBreaksBeforeNode
so that ‘(‘ and ‘last_name’ are on the same line and
| [node) fml_part
to _extraBrkBefore
so that they are both on a new line.
Now how could I align the ‘(‘, ‘,’ and ‘)’?
And secondly, any way we can right-align a SELECT, FROM, WHERE in a query?
Thanks again,
Stefan
pairwiseAlignments5: (
predecessor=node^-1-1
| predecessor=node^^-1-1
| predecessor=node^^^-1-1
| predecessor=node^^^^-1-1
)
& [predecessor) ‘(‘
& [predecessor^) fml_part
& [node) ‘,’
;
However, this solution doesn’t scale to arbitrary number of arguments. More elaborate fix is discussed here:
https://community.oracle.com/thread/4107800
Do you have a link to a documentation/tutorial on this format-code?
@NiceThoryVidar: I presume you are aware of this one https://vadimtropashko.files.wordpress.com/2017/02/arbori-starter-manual.pdf
Hi
How to align the following
PROCEDURE Tax_Val_Ptf (
P_Nptf IN Ptf.Nptf%TYPE
,
P_Noval IN NUMBER,
P_Mnt_Div IN NUMBER,
P_Carrondi IN NUMBER,
P_Cdec IN NUMBER,
P_Pct_Rctax IN OUT NUMBER,
P_Mnt_Rctax IN OUT NUMBER,
P_Pct_Untax IN OUT NUMBER,
P_Mnt_Untax IN OUT NUMBER,
P_Cretour IN OUT VARCHAR2,
P_Nproc IN OUT VARCHAR2,
P_Message IN OUT VARCHAR2,
P_Cetat IN OUT VARCHAR2
) IS
as
PROCEDURE Tax_Val_Ptf (
P_Nptf IN Ptf.Nptf%TYPE,
P_Noval IN NUMBER,
P_Mnt_Div IN NUMBER,
P_Carrondi IN NUMBER,
P_Cdec IN NUMBER,
P_Pct_Rctax IN OUT NUMBER,
P_Mnt_Rctax IN OUT NUMBER,
P_Pct_Untax IN OUT NUMBER,
P_Mnt_Untax IN OUT NUMBER,
P_Cretour IN OUT VARCHAR2,
P_Nproc IN OUT VARCHAR2,
P_Message IN OUT VARCHAR2,
P_Cetat IN OUT VARCHAR2
) IS
If i have only IN and OUT then the alignment is ok using the property
Line breaks on procedure arguments, if i have IN OUT, then the alignments are not OK
Regards,
Sumathi.V
Thank you for reporting this bug Sumathi. The workaround is to replace
[id+1) ‘IN’ | [id+1) ‘OUT’
with
[id+1) mode
in custom program.
Hi Vadim, is it possible to slightly change this rule and add 3 spaces before lonely ‘OUT’? The result would be that “IN” and “OUT” will be in nice two optical columns.
I agree that:
CREATE PROCEDURE tax_val_ptf ( p_nptf IN ptf.nptf%TYPE, p_noval IN NUMBER, p_mnt_div IN NUMBER, p_nproc OUT VARCHAR2, p_message IN OUT VARCHAR2, p_cetat IN OUT VARCHAR2 ) IS BEGINlooks little better. However just adding three spaces won’t be enough. This OUT alignment makes sense only in the presence of IN OUT arguments.
Thank you for your response. It’s really a pity that it can’t be done. Always three spaces before lonely OUT would be enough.
Is it possible to at least ignore this line? (with lonely OUT) and not formatting it?
I have changed these lines:
| :alignTypeDecl & ( :breaksAfterComma | :breaksBeforeComma ) & [id) decl_id & ([id+1) prm_spec_unconstrained_type | [id+1) mode ) & [scope) fml_part
| :alignTypeDecl & ( :breaksAfterComma | :breaksBeforeComma ) & [id) mode & [id+1) unconstrained_type & [scope) subprg_spec
replaced
[id+1) mode
with
([id+1) mode & ![id+1) ‘OUT’)
replaced [id) mode with
([id) mode & ![id) ‘OUT’)
This worked, but line was formatted by basic style, despite the fact that I have added line here:
dontFormatNode: [node) numeric_literal
| [node) ‘OUT’
Here is dontFormatNode rule amended to your spec (circa 19.1):
numericLiteral: [node) numeric_literal ; outParam: [node) prm_spec & [outMode) 'OUT' & outMode^ = node ; dontFormatNode: numericLiteral | outParam -> ;Thank you for your response.
I just realized there is a mess when I try to format the
IN OUT NOCOPY
combination
… do you have the same good advice?
This case is still governed by the amended dontFormatNode rule, which is rather accidental. The parse tree branch:
[8,13) prm_spec [8,9) decl_id identifier [9,10) 'IN' [10,11) 'OUT' [11,12) 'NOCOPY' [12,13) 'NUMBER' pls_number_datatypes unconstrained_type unconstrained_type_wo_datetimeis wrong, as there should be intermediate tree node labeled “mode”. I suggest modifying this line:
CREATE PROCEDURE proc_name ( param1 OUT NUMBER, param2 IN OUT NOCOPY NUMBER, param22 IN OUT NUMBER, param3 IN VARCHAR2, param4 IN VARCHAR2, p_table_name VARCHAR2, p_transaction_id NUMBER, p_calendar_code VARCHAR2, p_message_text VARCHAR2, p_column_names VARCHAR2, p_error_text OUT NOCOPY VARCHAR2 ) AS BEGIN NULL; END;Thank you for your response. I have also modified this rule:
| :alignTypeDecl & ( :breaksAfterComma | :breaksBeforeComma ) & [id) mode & [id+1) unconstrained_type & [scope) subprg_spec
… adding NOCOPY element like this:
| :alignTypeDecl & ( :breaksAfterComma | :breaksBeforeComma ) & (([id) mode & [id+1) unconstrained_type) | ([id) mode & [id+1) ‘NOCOPY’ & [id+2) unconstrained_type)) & [scope) subprg_spec
but it does not work. Do you have any good advice for me?
The syntax for the grammar rule involving NOCOPY is inconsistent– check the parse tree fragment from my previous reply. It should be the mode followed up by NOCOPY, but instead it is either IN OUT or OUT which is not recognized as a mode.
Hi
Thanks, the above solution worked
Regards,
Sumathi.V
Hi
I have few more queries
1st question
In the below code how to align the datatypes DATE, VARCHAR2, NUMBER etc.,
PROCEDURE Calc_Next_Dep(
P_Ddebut IN DATE,
P_Dfin IN DATE,
P_Cusance IN VARCHAR2,
P_New_Ddebut OUT DATE,
P_New_Dfin OUT DATE,
P_Cretour IN OUT VARCHAR2,
P_Nproc IN OUT VARCHAR2,
P_Message IN OUT VARCHAR2,
P_Cetat IN OUT VARCHAR2
) IS
2nd question
How to align the below cursor code as
CURSOR Cur_Tax IS SELECT Nvl(Pct_Un,0) Pct_Un,
Nvl(Pct_Rc,0) Pct_Rc
FROM T_Taxval
WHERE Nptf = P_Nptf
AND Noval = P_Noval;
as
CURSOR Cur_Tax IS
SELECT Nvl(Pct_Un,0) Pct_Un,
Nvl(Pct_Rc,0) Pct_Rc
FROM T_Taxval
WHERE Nptf = P_Nptf
AND Noval = P_Noval;
i.e., right align the keywords CURSOR, SELECT, FROM, WHERE AND
Thanks in advance
Regards,
Sumathi.V
Add one more padding condition:
| :alignTypeDecl & ( :breaksAfterComma | :breaksBeforeComma ) & [id) mode & [id+1) unconstrained_type & [scope) fml_part
Keyword right alignment option is there on Advanced Format panel since 18.1
Thanks it worked
Hi Vadim,
I’m new to playing with grammar like this and I was hoping you could help me out a bit.
Currently my code formats like
SELECT a.col_1
,b.col_2
FROM tab_a a
,tab_b b
And my desired output is
SELECT a.col_1
,b.col_2
FROM tab_a a
,tab_b b
I would like to carry this style through the WHERE clause as well but I’m trying to take it one step at a time (I did get the SELECT statement on my own!) I’ve tried doing
[node) ‘,’ & [node+1) table_expression,
[node) ‘,’ & [node+1) table_reference_or_join_clause, etc. But haven’t been able to get anything to work.
Would you be able to tell me how to achieve my desired output and tell me how you were able to figure it out? Any help is much appreciated!
Sorry Vadim, didn’t realize my formatting would get modified. Using periods for spaces.
Current format
SELECT a.col_1
…………..,b.col_2
….FROM tab_a a
……,tab_b b
Desired format
SELECT a.col_1
…………..,b.col_2
….FROM tab_a a
…………..,tab_b b
Your modified settings seems to be
alignRight (keywords) = true
breaksAfterSelect = false
breaksComma = before
You correct, the second line in the FROM clause is misaligned, which is a bug. Fixed for 18.3.
The fix/workaround: relocate the whole rightAlignments rule above paddedIdsInScope. This would make right alignments performed before aligning the table references.
Thanks Vadim, however this did not work as intended, it ended up left aligning my SQL but did align my tables and columns. I had another question I was hoping you could answer. In SQL Developer we are able to see the arbori through the custom format. I noticed each section was actually an arbori program. So my question is, can you tell me how the arbori programs are read by SQL Developer? For example, our first is simpleIndentConditions, what is running this program and how is it being used to indent the SQL?
@Parker
The parser, Arbori query engine, and their numerous applications, such as the formatter are the part of the dbtools-common library. This library has been briefly featured at GitHub, but was taken away because it exposed some proprietary code. Consequently, I had to take down couple of blog articles which have described how to use parser and arbori in your Java application. Still the management plans to eventually publish this library, so satisfactory answer to your question would be just pointing out to Java code that does it. For now, I could only hand wave, but let’s try. Each arbori rule calls java function with the same name via Java reflection, and those functions build the appropriate data structures, such as the map of all line breaks.
Hi
I have the following query, i have the following statement
IF P_Frequency NOT IN ( ‘0001’,’1001′,’0002′,’0003′,’0004′,’0005′,’0006′,’0007′,’0008′,’0009′,’0010′,’0011′,’0012′,’0013′,’0014′,’0015′,’0016′,’0017′,’0018′,’0019′,’0022′,’0023′
) THEN
RAISE Wrong_Frequency;
END IF;
I want to align as follows
IF P_Frequency NOT IN (‘0001′,’1001′,’0002′,’0003′,’0004′,’0005’,
‘0006’,’0007′,’0008′,’0009′,’0010′,’0011′,’0012′,’0013′,’0014′,’0015′,’0016′,’0017′,’0018′,’0019′,’0022′,’0023′) THEN
RAISE Wrong_Frequency;
END IF;
i.e. no line break after ‘IN (‘ or ‘NOT IN (‘ and also after the closing parenthsis ‘)’
Thanks in advance
Regards,
Sumathi.V
I think it worked, i have added the below which is marked as ‘– added this line
ignoreLineBreaksBeforeNode:
!:breaksBeforeComma & [node) ‘,’
| [node) ‘;’
| :breakAfterIf & [node) pls_expr & [node-1) ‘IF’
| [node) ‘)’ — added this line
->
;
ignoreLineBreaksAfterNode:
!:breaksAfterComma & [node) ‘,’
| [node) ‘,’ & [node-1) “expr_list”
| :breakAfterIf & [node) pls_expr & [node-1) ‘IF’
| [node) ‘(‘ — added this line
->
;
Not sure whether the solution is correct or not
Regards,
Sumathi.V
Hi
How to give line break between IS and SELECT in the below cursor statement
CURSOR Cur_Tax IS SELECT Nvl(Pct_Un,0) Pct_Un,
Nvl(Pct_Rc,0) Pct_Rc
FROM T_Taxval
WHERE Nptf = P_Nptf
AND Noval = P_Noval;
Now using version 18.1
Regards,
Sumathi.V
Add
| [node) ‘IS’ & [node-1) cursor_d
to _extraBrkAfter rule.
I have added only | [node-1) cursor_d it worked, when i added the above as suggested, it was giving error
Regards,
Sumathi.V
Make sure the single quotes around the AS keyword has not been transformed during copying and paste.
Hi,
In fact i have three queries related to cursors
In the below cursor
CURSOR Cur_Details ( Vc_Ntransac T_Re_Trns_Mst.Ntransac%TYPE,
Vc_Noutlet T_Re_Trns_Mst.Noutlet%TYPE ) IS SELECT Nregister,
Proxy,
Nprod,
Nprod_Transf,
Ntfc,
Ntfc_Transf
FROM T_Re_Trns_Mst
WHERE Ntransac = Vc_Ntransac
AND Noutlet = Vc_Noutlet
AND Coperation IN ( ‘0018’,’0020′,’0033′,’0082′ );
1. Want to line break between IS and SELECT
2. Want to right align corners CURSOR, SELECT, FROM, WHERE, AND (if right align option of 18.1 is used it aligns only SELECT, FROM and WHERE)
3. The cursor variable VC_NTRANSAC, VC_NOUTLET is to be aligned one below the other (similar to the procedure agrugments)
Regards,
Sumathi.V
Hi
When i added | [node-1) cursor_d in the _extraBrkAfter rule, all the above issues got solved.
Thanks,
Sumathi.V
Hi,
I have the following query, currently i have a cursor as follows
Cursor C_Min_Limit_All Is
Select Type_Id_Code, Id_Code, Nptf, Tpart, Cmon
From T_Ta_Investment_Limit
Where Type_Id_Code = Vc_Type_Id_Code
And Id_Code = Vc_Id_Code
Order By Decode(Tpart,’@@@@’,1,0);
i want to retain the select statement section below
Select Type_Id_Code, Id_Code, Nptf, Tpart, Cmon
as it is , since i have opted for break after comma, the select list is getting re-aligned as follows
Select Type_Id_Code,
Id_Code,
Nptf,
Tpart,
Cmon
Is there any way to handle this.
Regards,
Sumathi.V
1. Disable indentation of select_list which is controlled via condition
| :breaksAfterSelectFromWhere & [node) select_list & [node^) select_clause
This can be done either with flipping the corresponding option at Advanced Format settings or editing this line at the Custom Format page
2. Disable breaks after comma which is controlled in two places
| :breaksAfterComma & [node+1) select_term & [node) ‘,’
…
| :breaksAfterComma & ([node+1) expr | [node+1) column) & [node) ‘,’
& ![node^) aggregate_function & ![node^) analytic_function
This condition, again, can be disabled either from advanced format page, or explicitly in the arbori code. Since you have mentioned that you don’t want to set line breaks on commas to None, then just comment these lines at the Custom Format page
These exact formatting conditions are described in more recent article
Hi,
The above changes is bringing all the select list columns in single line.
Actually my question was
I have the following query, currently i have a cursor as follows
Cursor C_Min_Limit_All Is
Select Type_Id_Code, Id_Code,
Nptf, Tpart, Cmon
From T_Ta_Investment_Limit
Where Type_Id_Code = Vc_Type_Id_Code
And Id_Code = Vc_Id_Code
Order By Decode(Tpart,’@@@@’,1,0);
i want to retain the select statement section as it is how the developer had typed (i.e., no comma breaks for select_list)
Select Type_Id_Code, Id_Code,
Nptf, Tpart, Cmon
Regards,
Sumathi.V
There is no method to preserve a section of the code such as select_clause. The only option for “partial formatting” sqldev offers is “Convert case only” at the basic format page. There is also another option, which might help – “Max char line width”. Admittedly, it is the least intelligent of the formatting features, as it would just wrap a long line exceeding some character length limit.
I’m using Sql Developer Ver 19.2.1.247 and I’ve the following statement, where the in_condition need to be aligned in single line
SELECT a
,b
,c
FROM perks_basket_purchase
WHERE str_no IN(
8148
)
AND tx_dte_tme BETWEEN TO_DATE(‘20190802′,’YYYYMMDD’)AND TO_DATE(‘20190831′,’YYYYMMDD’)
AND trml_no = 0
AND tx_no = 0;
I want to align as follows
SELECT a
,b
,c
FROM table1
WHERE str_no IN (0)
AND tx_dte_tme BETWEEN TO_DATE ( ‘20190802’, ‘YYYYMMDD’) AND TO_DATE ( ‘20190831’, ‘YYYYMMDD’)
AND trml_no = 0
AND tx_no = 0;
Also is there is way to automatically generate tagline with header comments to show when the code was Formatted on
/* Formatted on 12/9/2019 11:17:20 AM */
SELECT a
,b
,c
FROM table1
WHERE str_no IN (0)
AND tx_dte_tme BETWEEN TO_DATE ( ‘20190802’, ‘YYYYMMDD’) AND TO_DATE ( ‘20190831’, ‘YYYYMMDD’)
AND trml_no = 0
AND tx_no = 0;
Thanks,
Dilly
| .breaksProcArgs & [node) “expr_list” & [node^) “(x,y,z)” & ![node) compound_expression & ![node) identifier
–| [node) expression_list & ![node) grouping_expression_list
| [node) external_table_data_props
| :breaksBeforeComma & [node^) group_by_list[5,12) & [node) ‘,’
–| :breaksBeforeComma & [node+1) expr & [node) ‘,’
| :breaksBeforeComma & [node+1) column & [node) ‘,’
— additional rule:
timestamp: runOnce -> {
var date = new java.util.Date();
struct.putNewline(0, “/* Formatted on “+date+” */\n”);
}
—- Output —–
/* Formatted on Mon Dec 09 11:56:55 PST 2019 */ SELECT a , b , c FROM table1 WHERE str_no IN ( 0 ) AND str_no IN ( 0, 1 );Thanks Vadim for your reply.
— additional rule:
timestamp: runOnce -> {
var date = new java.util.Date();
struct.putNewline(0, “/* Formatted on “+date+” */\n”);
}
Your code helped to automatically create the header comment, however it append the header comment when the code is formatted multiple times.
/* Formatted on Mon Jan 06 11:57:42 EST 2020 *//* Formatted on Mon Jan 06 11:57:44 EST 2020 */
Is is possible to override the header comment, when the code is formatted multiple times.
/* Formatted on Mon Jan 06 11:57:44 EST 2020 */
Thanks,
Dilly
Not possible in 19.4. I have amended the code for 20.1. The timestamp rule is the last, but is disabled by default like this:
timestamp: runOnce & false -> {
…
Just remove or comment the “false” literal in order to enable it.
If the header comment can’t be override in 19.4, is it possible to remove the first line of the code, if the code contain the string %Formatted on%
Technically, the formatting core functionality is written in Java and, therefore, can’t be hacked. In 19.4 the input text is not accessible to the Nashorn scripting that I’m using in the custom format program. I fixed it for 20.1.
Thanks Vadim for your code on the header comment.
We are migrating from Toad to Sql developer and below are few requirement to format the code on the Sql developer.
I would really appreciate, if you could help me out.
1) Line break after the hint on the Select
SELECT /*+ use_hash(rtd st incl str) */ rtd.str_no AS str_no
,TRUNC (rtd.tx_dte_tme) AS tx_dte
,NVL (st.trml_typ_cd,’UNK’) AS trml_typ_cd
Expected:
SELECT /*+ use_hash(rtd st incl str) */
rtd.str_no AS str_no
,TRUNC ( rtd.tx_dte_tme) AS tx_dte
,NVL (st.trml_typ_cd, ‘UNK’) AS trml_typ_cd
2) Extra line break before Cursor declaration only when variable/constant defined above.
c_defaultBsStrNo CONSTANT STORE.str_no%TYPE := 0;
CURSOR l_rtlTndrDtlCur IS
SELECT * from dual
Expected
c_defaultBsStrNo CONSTANT STORE.str_no%TYPE := 0;
CURSOR l_rtlTndrDtlCur IS
SELECT * from dual
3) Remove line beak on Procedure / Function / Cursor parameter declaration. Line break are need only when the declaration exceeds MAX CHAR LINE WIDTH
PROCEDURE insTndrOnly (
p_runDte IN DATE
,p_txDte IN DATE
);
Expected :
PROCEDURE insTndrOnly (p_runDte IN DATE, p_txDte IN DATE);
4) When invoking the procedure, line breaksBeforeComma on each parameter and also parenthesis need to be aligned
SELECT a
,b
FROM TABLE (transformRTDForInsOfOneActnCd (p_runDte,p_txDte,c_tndrActnCd,c_crctnActnCd,c_chgActnCd));
Expected:
SELECT a
,b
FROM TABLE (transformRTDForInsOfOneActnCd (p_runDte
,p_txDte
,c_tndrActnCd
,c_crctnActnCd
,c_chgActnCd
)
);
5) if_stmt – Line break before on the and_expr.
IF (l_prevStrNo = l_strNo) AND (l_prevTrmlNo = l_trmlNo) AND (l_prevTxNo = l_txNo) AND (l_prevTxDte = l_txDte) AND (l_prevTrmlTypCd = l_trmlTypCd) AND (l_prevRunDTe = l_runDte
Expected:
IF (l_prevStrNo = l_strNo)
AND (l_prevTrmlNo = l_trmlNo)
AND (l_prevTxNo = l_txNo)
AND (l_prevTxDte = l_txDte)
AND (l_prevTrmlTypCd = l_trmlTypCd)
AND (l_prevRunDTe = l_runDte)
Thanks in Advance
Embedding code in the wordpress comment section is nontrivial. Therefore, can you please post your requirements on stackoverflow (under the tag oracle-sqldeveloper) or the OTN forum? Please also be specific what Advanced Format options you have changed, and give little more context to the code snippets (for example, the IF statement in your last case, was it from SQL or PL/SQL?)
I’ve posted my requirements on the OTN forurm
https://community.oracle.com/message/15535152#15535152